Amikor blogbejegyzést írok, szinte mindig olyan projektekről vagy szoftverekről írok, amik már lezárultak vagy fejlesztésük véget ért, “kiforrott” szoftvernek lehet nevezni őket.
Részben kedvtelésből, részben pedig munkámhoz kapcsolódóan kellett elmélyülnöm egy picit az AI által segített adatfeldolgozásban és a piacon elérhető, integrálható AI-modellekkel.
A probléma
Először is, a legnagyobb gond az volt, hogy bődületes mennyiségű adatot kellett feldolgozni, másodszor pedig ezek az adatok speciálisak voltak: több mint 40 órányi hanganyagról van szó. Ezeket a hanganyagokat egy szakértői csoport fogja kiértékelni, akik viszont nem tartanak igényt a hangokra, csak az ezekből generált átiratokra.
Fontos az is, hogy az átiratokat nem csak előállítani kell tudni, hanem a tárolásukat is meg kellene oldani valamilyen módon.
Megoldási kísérlet
Most ezen a ponton érdemes lenne elmondani, hogy a “megoldásom” azért nem annyira komoly, mivel maga az AI-rész már készen, API-n keresztül jön be hozzám, a szoftver feladata az API hívások koordinálása, a modellek megfelelő promptolása és a visszaérkező anyagok gyűjtése és aggregálása. Tehát lényegében írtam egy nagyon speciális dashboardot egy speciális feladathoz. De azért vannak benne csavarok.
A munka nagy részét az OpenAI modelljei végezték, név szerint a Whisper (Speech to text) és a GPT-család tagjai (erről később lesz szó).
A szoftver a következő dolgokat teszi lehetővé, ezeket részletezem a továbbiakban:
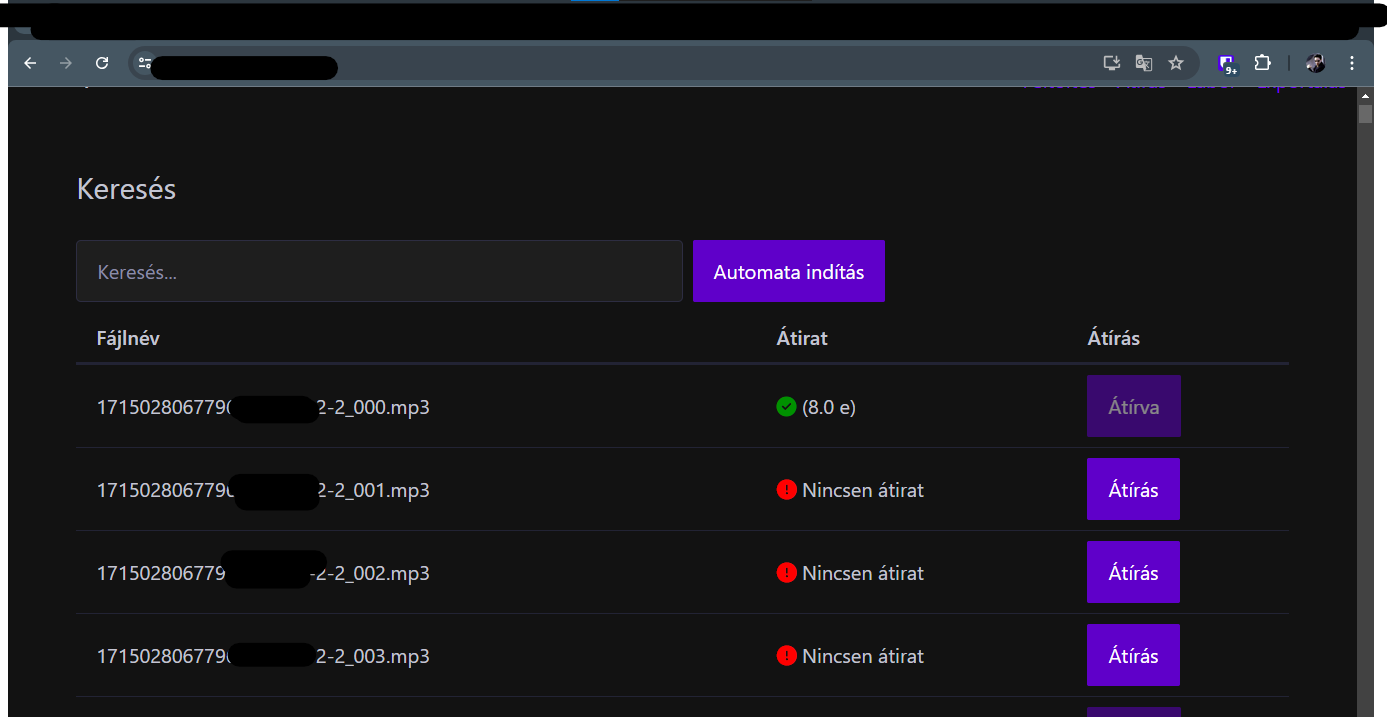
- Hanganyagok feltöltése Drag n’ Drop jelleggel, ezek automatikus felvétele
- A hanganyagok kezdetleges szöveggé alakítása (nyers átirat)
- A nyers átiratokon belül a beszélők (interjúalany és interjút készítő) elkülönítése (angolul diarisation)
- Minden részfolyamat után automatikus ellenőrzés
- Költségbecslések a modellhasználatra
Munka a hanggal – Whisper
Azért döntöttem a Whisper mellett, mivel elég olcsó (olyan 0.01$ percenként), így egy interjú (átlagban 60 perc) olyan 0.6 dollárból (jobb napokon 220 forint) kijön. Ez emberi munkaórában és bérben is több lenne, tehát itt már nyertünk egy picit (de erről később).
A modellel való kísérletezés során több dolgot is megtanultam:
- Van fájlméret limit (25 MB), így fel lehet tölteni mindent akár egyben, de nem érdemes így használni, mert a későbbiekben megint szét kell szedni több részre az anyagot. Az én szoftverem tíz perces sávokkal dolgozik, amelyeket egy gyönyörű egysoros FFMPEG-parancs állít elő.
exec('ffmpeg -i ' + 'largeFiles/' + req.files[i].originalname + ' -f segment -segment_time 10:00 -c copy ' + 'largeFiles/' + req.files[i].filename.split(".")[0] + '_%03d.' + req.files[i].filename.split(".")[1], (err, stdout, stderr) => {
if (err) {
console.log(err);
res.status(500).send('Error uploading file');
return;
}
- Bár a modell ért magyarul, azért a tájszólásokkal gondja akad, szinte mindig. Itt ennek ékes példája az egyik interjúban a “pótkocsi” szó. Leírva pótkocsi, de kimondva vagy p[au]tkocsi vagy vagy pó[t]kocsi. Erre megoldást úgy lehet találni (esetleg), hogyha a Whisper system promptjába beírjuk a problémásabb szavakat előre (de ehhez persze ismerni kell az anyagot)
- A rendszer inkább szótagokat ismer fel, mint szavakat, tehát a nyakatekertebb összetett szavakba sajnos gyakran beletörik a bicskája (de kinek nem?). Itt is system prompt marad vagy a manuális javítás (szótárral kísérleteztem, több-kevesebb sikerrel).
- Előfordul, hogy a felvételen egymás szavába vágnak az emberek, ilyenkor teljesen esélytelen, hogy bármit is kihámozzon az automata, mivel még embernek sem olyan egyszerű kitalálni, hogy mi történik.
A felvétel hangereje teljesen mindegy, a suttogást és a kiabálást is érti, akár közvetlen egymás után is. Ez hasznos, mert nem kell előfeldolgozni magát a hangot.
Szöveges feladat – Utófeldolgozás
Itt bajban voltunk, mivel a Whisper az csak folyószöveget képes előállítani (megbízhatóan), szóval utólag kellett elvégezni a beszélőkre bontást. Erre speciális modellek és megoldások vannak (érdekes, mert nincsen ehhez npm library), de itt nem volt idő ezek implementációjára, így inkább fejjel mentem a falnak: az API-n keresztül meghívtam egy GPT-modellt.
Először a GPT-4 volt a tervezett modell, de gyorsan rá kellett jönnöm, hogy itt elég nagy gond az ár (30$ / 1 millió token). Ezért végül (egy kis gpt-3.5-turbo-s bénázás után) a legújabb modellre, a GPT-4o-ra esett a meglehetően szakmai és megalapozott (nem) döntésem. Itt főleg az vezérelt valójában, hogy a 4o ára a GPT-4 modell árának egyhatoda (5$ / 1 millió token).
Itt írtam egy gyors system promptot, ami arra utasítja a modellt, hogy különítse el a beszélőket és minden blokk elejére tegyen egy kötőjelet, a blokkokat pedig egy sortöréssel (néha kettővel sikerült) zárja le. A tisztánlátás végett a webalkalmazás ilyenkor helyileg tokenekre bontja a szöveget és költségbecslést is ad.
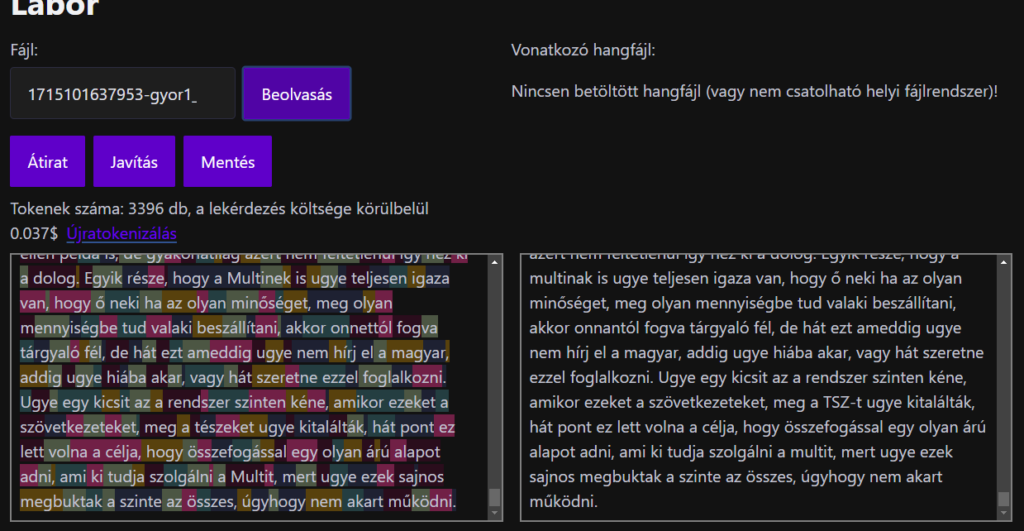
Pár észrevétel:
- Érdemes a tokenlimitet betartani, mert ha túllépjük a kontextust, akkor könnyen butaságokat küldhet vissza a modell.
- Előfordul, hogy a modell megkeveredik és kihagy részeket. Ezt a system prompt módosításával lehet meggátolni. Így viszont feldolgozatlanul hagyhat részeket a gép.
Zárszó – Kinek jó ez?
Röviden: nagyon sok mindenkinek. Ebben az esetben (és még számos területen) az AI egy gyors és viszonylag pontos megoldást ad egy emberrel szemben, gyakran az eredeti ár töredékéért. Ez azért jó, mert így le lehet venni az emberek válláról a felesleges munka terhét.
Azonban azt is szem előtt kell tartani, hogy szinte minden esetben fontos az, hogy mit ad ki az AI, mivel függhet tőle az, hogy sikerül-e elvégezni a feladatot, sőt akár ennél fontosabb, emberéleteket veszélyeztető helyzetek is kialakulhatnak, ha az AI nincsen megfelelően felügyelve. Ennél a szoftvernél a felügyeletet két részre lehet tagolni: a labor fülön pontosan látjuk azt, hogy az AI mit lát (tokenek), illetve azt, hogy mit ad ki, ezeken módosíthatunk is. Az egyetlen változatlan dolog itt a system prompt. Ezen kívül az AI “hallucinálhat” is, így nem létező részeket beillesztve vagy valódi részeket kihagyva. Nagyon kell figyelni a bemenet és a kimenet hossza közti kapcsolatra (a kimenet szinte mindig hosszabb, mint a bemenet, általában a bemenet hosszának kb. 120%-a).
Itt az AI nagyon sok munkaórát megspórolt, illetve megkönnyítette egy emberfeletti feladat elvégzését, de én még mindig azt gondolom, hogy az AI-technológiára vakon hagyatkozni nem lehet, csakis kizárólag megfelelő kontroll mellett lehet ezeket a megoldásokat alkalmazni.
Leave a Reply